

どうも、カメ助(@kamesuke_blog)です。
そこで今回はSeleniumを使用してYouTubeを「スクレイピング」するプログラムを紹介します。(windows環境)
前半でサンプルコードを紹介、後半でサンプルコードを解説の順で説明していきます。
 カメ助
カメ助この記事はこんな人にオススメ
・YouTubeの「スクレイピング」の仕方が知りたい
・「スクレイピング」のサンプルコードがほしい
皆さんがスクレイピングする際の参考になれば嬉しいです。
スクレイピングのサンプルコード

YouTubeのデータの内、スクレイピングで取得するものとしては「タイトル」、「動画のURL」が挙げられます。
そこで今回は、YouTubeの急上昇(音楽)の動画タイトル・動画のURLをCSVファイルに書き出すコードを紹介します。(画面の操作はSeleniumを使用しています。)
処理の流れ
サンプルコードの処理は以下の流れで行います。
- YouTubeの急上昇のサイトにアクセスする
- YouTubeの急上昇のサイト内の「音楽」タブをクリックする
- ページの情報を取得する
- 取得結果をCSVファイルに出力する
サンプルコードの動作確認環境
本サンプルでは、PythonとSeleniumを使用しています。(Windows環境)
- OS : Windows10
- 言語 :Python
- ツール :Selenium (chromedriverを使用)
- エディタ :VSCode
- ブラウザ :GoogleChrome
サンプルコード
コメントで簡単な説明を記載していますので参考にしてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
from selenium import webdriver from selenium.webdriver.chrome.options import Options import pandas as pd from time import sleep #windows(chromedriver.exeのパスを設定) chrome_path = r'C:\Users\デスクトップ\python\selenium_test\chromedriver' #mac #chrome_path = 'C:/Users/デスクトップ/python/selenium_test/chromedriver' #YouTubeの急上昇(音楽)ぺージのデータを10件取得しCSV出力 def get_youtube_trending_music_info(url,outputFileName): options = Options() # オプションを用意 options.add_argument('--incognito') # シークレットモードの設定を付与 # chromedriverのパスとパラメータを設定 driver = webdriver.Chrome(executable_path=chrome_path,options=options) driver.get(url) # chromeブラウザでurlを開く driver.implicitly_wait(10) # 指定したドライバの要素が見つかるまでの待ち時間を設定 xpath = '//*[@id="tabsContent"]/tp-yt-paper-tab[2]' #急上昇の音楽タブのxpathを設定 driver.find_element_by_xpath(xpath).click() #音楽のタブをクリック sleep(2) # 再読み込みのために2秒待つ #ランキング情報を取得 music_ranking_videos = driver.find_elements_by_id('video-title') #トップ10の情報(動画タイトルとURL)を格納する変数を用意 titles = [] urls = [] #トップ10の情報を抽出する for music_ranking_video in music_ranking_videos: #titlesに動画タイトルを格納 titles.append(music_ranking_video.text) #urlsに動画URLを格納 urls.append(music_ranking_video.get_attribute('href')) #10件処理したら終了 if len(titles) == 10: break #取得したデータの整形を行う #DataFrameの準備 df = pd.DataFrame() #データを設定する df['trending_rank'] = range(1,11) #急上昇ランキング1位から10位 df['title'] = titles df['URL'] = urls #データをCSVで出力する df.to_csv(outputFileName) #chromeブラウザを閉じる driver.quit() #インポート時は実行されないように記載 if __name__ == '__main__': #Youtubeの急上昇ページ url = 'https://www.youtube.com/feed/trending' #データを書きだすファイル名 outputFileName = 'youtube_trending_music_rank.csv' #YouTubeの急上昇(音楽)ぺージのデータを10件取得しCSV出力 get_youtube_trending_music_info(url,outputFileName) |
出力ファイル(一部抜粋)
サンプルコードを実行すると以下のようなCSVファイル(youtube_trending_music_rank.csv)が出力されます。
実際の業務では、出力したCSVファイルの内容を分析していきます。
|
1 2 3 4 5 6 7 8 9 10 11 |
,trending_rank,title,URL 0,1,NiziU(니쥬) 2nd Single 『Take a picture』 MV,https://www.youtube.com/watch?v=OlHb1qH-zS4 1,2,Snow Man「Black Gold」(from「滝沢歌舞伎 ZERO 2020 The Movie」),https://www.youtube.com/watch?v=HCLy5Ir48lU 2,3,YOASOBI「優しい彗星」Official Music Video (YOASOBI - Comet),https://www.youtube.com/watch?v=VyvhvlYvRnc 3,4,宇多田ヒカル『One Last Kiss』,https://www.youtube.com/watch?v=0Uhh62MUEic 4,5,廻廻奇譚 - Eve MV(Live Film ver),https://www.youtube.com/watch?v=ijXeGqSRNJc 5,6,JO1|'Born To Be Wild' Official MV,https://www.youtube.com/watch?v=-_P_cD0yimw 6,7,スピッツ / 紫の夜を越えて,https://www.youtube.com/watch?v=nqjkgsRD7Sw 7,8,関西ジャニーズJr.「BIG GAME」(あけおめコンサート2021〜関ジュがギューっと大集合〜),https://www.youtube.com/watch?v=DIprjjAYZeU 8,9,誇り高きアイドル/HoneyWorks feat.Kotoha,https://www.youtube.com/watch?v=Qou76O_Rys0 9,10,優里 『ドライフラワー』 Official Music Video -ディレクターズカットver.-,https://www.youtube.com/watch?v=kzZ6KXDM1RI |
続いてサンプルコードの内容について説明していきます。ソースコード見れば内容がわかる方は、読み飛ばしても問題ないです。
サンプルコードの解説
ここからはサンプルコードの内、YouTubeにアクセスする部分について解説します。
まず、メソッド「get_youtube_trending_music_info」に引数として以下のパラメータを渡します。
- url : YouTubeのURL
- outputFileName : CSVファイル名
Seleniumのパラメータを設定し、urlにアクセスしています。
|
1 2 3 4 5 6 7 |
options = Options() # オプションを用意 options.add_argument('--incognito') # シークレットモードの設定を付与 # chromedriverのパスとパラメータを設定 driver = webdriver.Chrome(executable_path=chrome_path,options=options) driver.get(url) # chromeブラウザでurlを開く driver.implicitly_wait(10) # 指定したドライバの要素が見つかるまでの待ち時間を設定 |
上記でYouTubeの急上昇タブのページにアクセスします。しかし、初期表示では最新タブを選択した状態になっています。
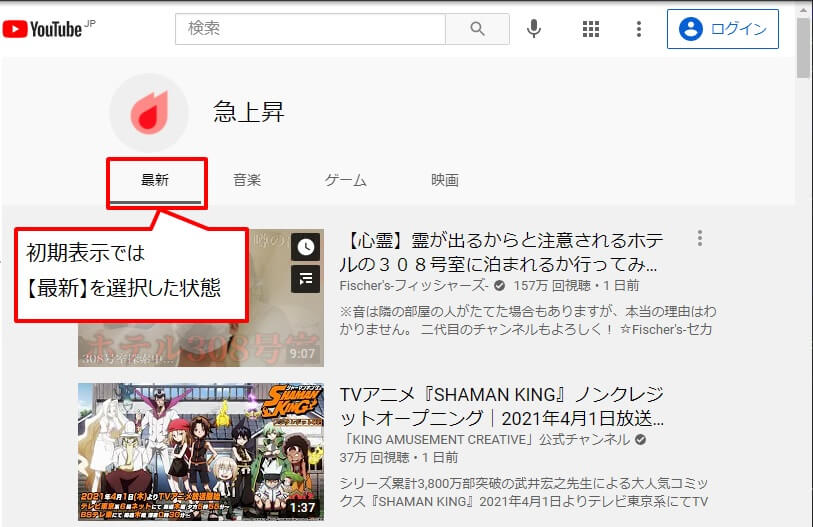
今回は音楽タブの情報を取得したいので、Seleniumで音楽タブをクリックする必要があります。
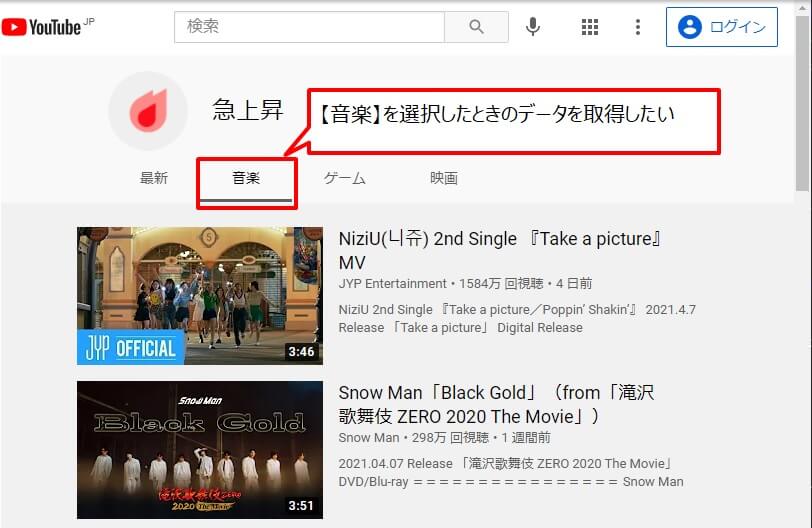
Seleniumで音楽タブをクリックするために、以下の手順で対応していきます。
- 音楽タブの要素を指定する
- 指定した要素をクリックする
まず、音楽タブの要素を指定していきます。一般的に対象の要素を指定方法は、エレメントのidやclass名を指定する方法があります。
しかし、HTMLを調査するとエレメントのidやclassが他のタブと同一でした。そのため、今回はxpathで判別しています。
以下で音楽タブのxpathを設定します。xpathの取得方法については以下の記事を参考にしてください。

|
1 |
xpath = '//*[@id="tabsContent"]/tp-yt-paper-tab[2]' #急上昇の音楽タブのxpathを設定 |
取得したxpathをクリックし、画面読み込み時間として2秒待ちます。
|
1 2 |
driver.find_element_by_xpath(xpath).click() #音楽のタブをクリック sleep(2) # 再読み込みのために2秒待つ |
次に、ページ内のエレメントidが「video-title」のデータをすべて取得します。
|
1 |
music_ranking_videos = driver.find_elements_by_id('video-title') |
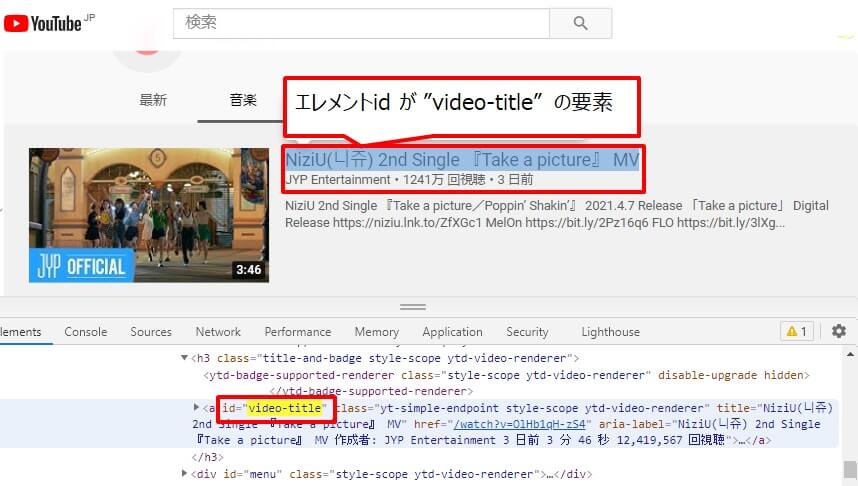
「video-title」のデータをfor-in文で繰り返し、titlesに「動画のタイトル」、urlに「動画URL」を格納します。10件分のデータ取得を行うと繰り返し処理を終了しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#トップ10の情報(動画タイトルとURL)を格納する変数を用意 titles = [] urls = [] #トップ10の情報を抽出する for music_ranking_video in music_ranking_videos: #titlesに動画タイトルを格納 titles.append(music_ranking_video.text) #urlsに動画URLを格納 urls.append(music_ranking_video.get_attribute('href')) #10件処理したら終了 if len(titles) == 10: break |
取得データを整形してCSVファイルに出力します。今回はPythonライブラリのPandas(パンダス)を使用しています。
|
1 2 3 4 5 6 7 8 9 10 11 |
#取得したデータの整形を行う #DataFrameの準備 df = pd.DataFrame() #データを設定する df['trending_rank'] = range(1,11) #急上昇ランキング1位から10位 df['title'] = titles df['URL'] = urls #データをCSVで出力する df.to_csv(outputFileName) |
最後にブラウザを閉じます。
|
1 2 |
#chromeブラウザを閉じる driver.quit() |
まとめ
今回は、YouTubeをスクレイピングするサンプルコードの紹介をしました。
今回のサンプル作成にあたって、xpathの取得方法について学べました。xpathを使用する方法は、今後スクレイピングをする際によく使用することになると思うのでさらに勉強していきます。
ちなみに、YouTubeの情報を集めるには、今回紹介したスクレイピングやYouTube Data APIを使用する方法があります。
YouTube Data APIを使用したサンプルについては別の機会に紹介できればと思います。
カメ助記事内容について、質問などありましたら気軽にコメントください!







コメント