

こんにちは、カメ助(@kamesuke_blog)です。
Pythonでスクレイピングする際に毎回HTMLの構造解析が必要なんですが、このHTMLの構造解析が非常に面倒で、
 カメ助
カメ助何とかならないかな。。。
と、ネットで調べたところXPathによる情報抽出が有効であるとの情報がありました。
今回は、Chromeの標準機能でXPathを取得する方法についてまとめていきます。
カメ助この記事はこんな人にオススメ
・「XPath」って何?
・「XPath」の取得方法が知りたい
スクレイピングする際にはXPathを活用していきたいと思います。
XPathとは
XPathはXML文章中の要素、属性値などを指定するための言語です。
Qiitaより
XPathではXML文章をツリーとして捉えることで、要素や属性の位置を指定することができます。
HTMLもXMLの一種とみなすことができるため、XPathを使ってHTML文章中の要素を指定することができます。
一言でいうと、XPathはHTMLやXMLから特定の部分を指定できるものです。
カメ助XPathを使うとスクレイピングしたい場所を簡単に指定できるよ
XPathを使用することで、HTMLの構造解析せずにスクレイピングができるようになります。続いてXPathの取得方法を見ていきます。
XPathの取得方法
XPathの取得方法は以下の3ステップです。
- XPathを取得したい要素の上で「右クリック」→「検証」をクリック
- XPathを取得したい要素の上で「右クリック」→「Copy」→「Copy XPath」をクリック
- クリップボードにXPathがコピーされる
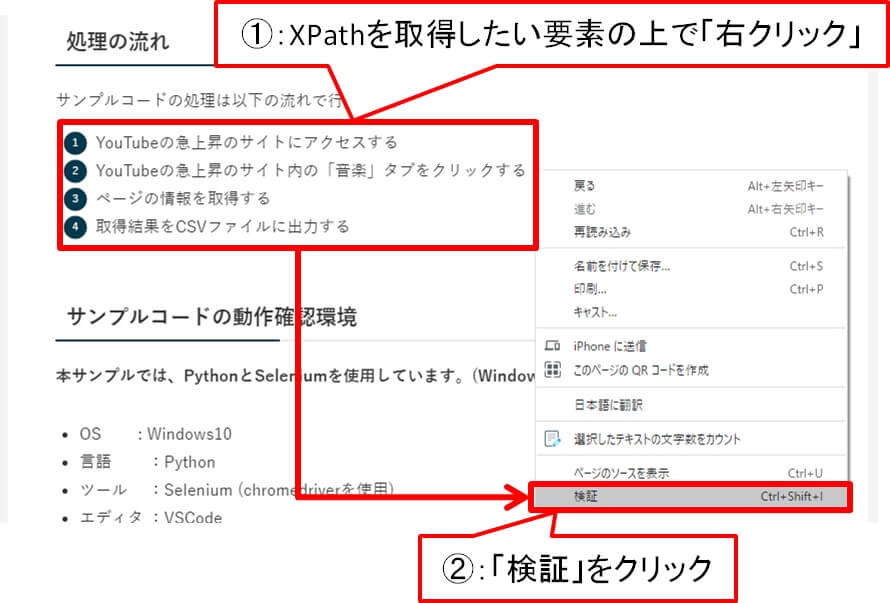
①:XPathを取得したい要素の上で「右クリック」→「検証」をクリック
最初にxpathを取得したい要素の上で「右クリック」し、その後「検証」をクリックします。
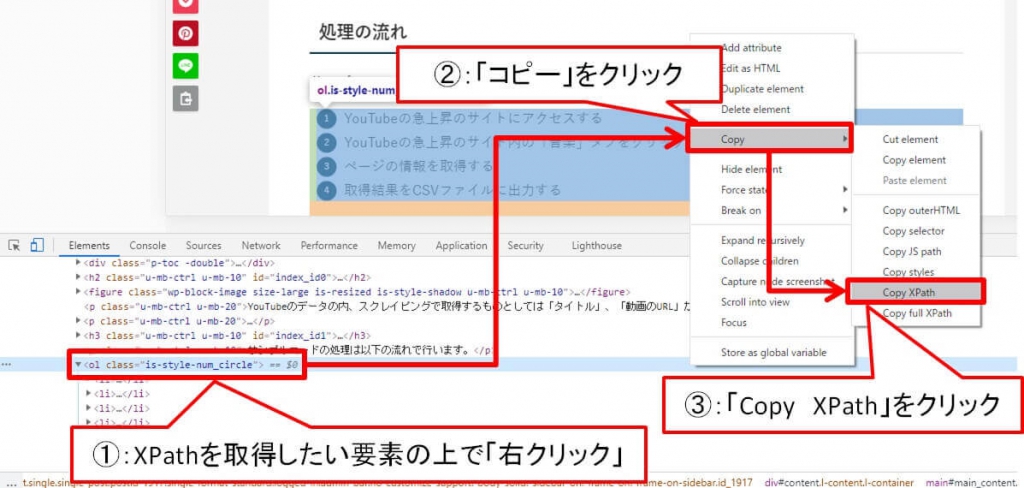
②:XPathを取得したい要素の上で「右クリック」→「Copy」→「Copy XPath」をクリック
開発者ツールが表示されるので、対応する要素(今回はol要素)の上で「右クリック」し、「Copy」→「Copy XPath」とクリックします。
③:クリップボードにXPathがコピーされる
するとクリップボードに以下のようなXPathがコピーされます。スクレイピングをするプログラムに貼り付けて使用しましょう。
|
1 |
//*[@id="main_content"]/article/div[3]/ol[1] |
XPathの使用例
最後にXPathの使用例について見ていきましょう。
以下のサンプルは、カメ助ブログのページをスクレイピングするものです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from time import sleep # スリープを使うために必要 from selenium import webdriver # Webブラウザを自動操作するためのツールseleniumを使用 from selenium.webdriver.chrome.options import Options # seleniumのオプションを使用 # windows(chromedriver.exeのパスを設定) chrome_path = r'C:\Users\zeros\OneDrive\デスクトップ\python\selenium_test\chromedriver' # seleniumのパラメータを設定 options = Options() # seleniumのオプションを用意 options.add_argument('--incognito') # シークレットモードの設定を付与 # chromedriverのパスとパラメータを設定 driver = webdriver.Chrome(executable_path=chrome_path,options=options) # サンプルのHTMLを開く driver.get('https://kamesuke-blog.com/programming/scraping_youtube/') sleep(1) # 1秒間待機 # xpathで指定してfind関数で要素をリストで取得 xpath = '//*[@id="main_content"]/article/div[3]/ol[1]' # Chromeで取得したのXPathを指定 elements = driver.find_elements_by_xpath(xpath) # XPathで指定した要素を取得 # 取得した要素を1つずつ表示 for element in elements: print(element.text) # 要素の情報を表示 driver.quit() # ブラウザを閉じる |
ちなみに以下の場所にXPathを使用しています。
|
1 |
xpath = '//*[@id="main_content"]/article/div[3]/ol[1]' |
このコードを実行すると、Chromeブラウザが自動で立ち上がり、コンソールに以下の出力表示されます。
|
1 2 3 4 |
YouTubeの急上昇のサイトにアクセスする YouTubeの急上昇のサイト内の「音楽」タブをクリックする ページの情報を取得する 取得結果をCSVファイルに出力する |
以上の結果より、指定した要素の文章情報だけが抽出できていることが分かります。
終わりに
今回はChromeの標準機能で、XPathを取得する方法について紹介しました。XPathを使用することで、HTMLの構造について考えなくて済むのでスクレイピングの作業効率が上がりました。
また、今回の方法はツールなどの追加インストールが不要なので環境依存しないのも嬉しいですね。
XPathを使用してYouTubeのスクレイピングを行ったサンプルはこちら







コメント